linux系统简单了解
目录结构:
-
bin (binaries)存放二进制可执行文件
-
sbin (super user binaries)存放二进制可执行文件,只有root才能访问
-
etc (etcetera)存放系统配置文件
-
usr (unix shared resources)用于存放共享的系统资源
-
home 存放用户文件的根目录
-
root 超级用户目录
-
dev (devices)用于存放设备文件
-
lib (library)存放跟文件系统中的程序运行所需要的共享库及内核模块
-
mnt (mount)系统管理员安装临时文件系统的安装点
-
boot 存放用于系统引导时使用的各种文件
-
tmp (temporary)用于存放各种临时文件
-
var (variable)用于存放运行时需要改变数据的文件

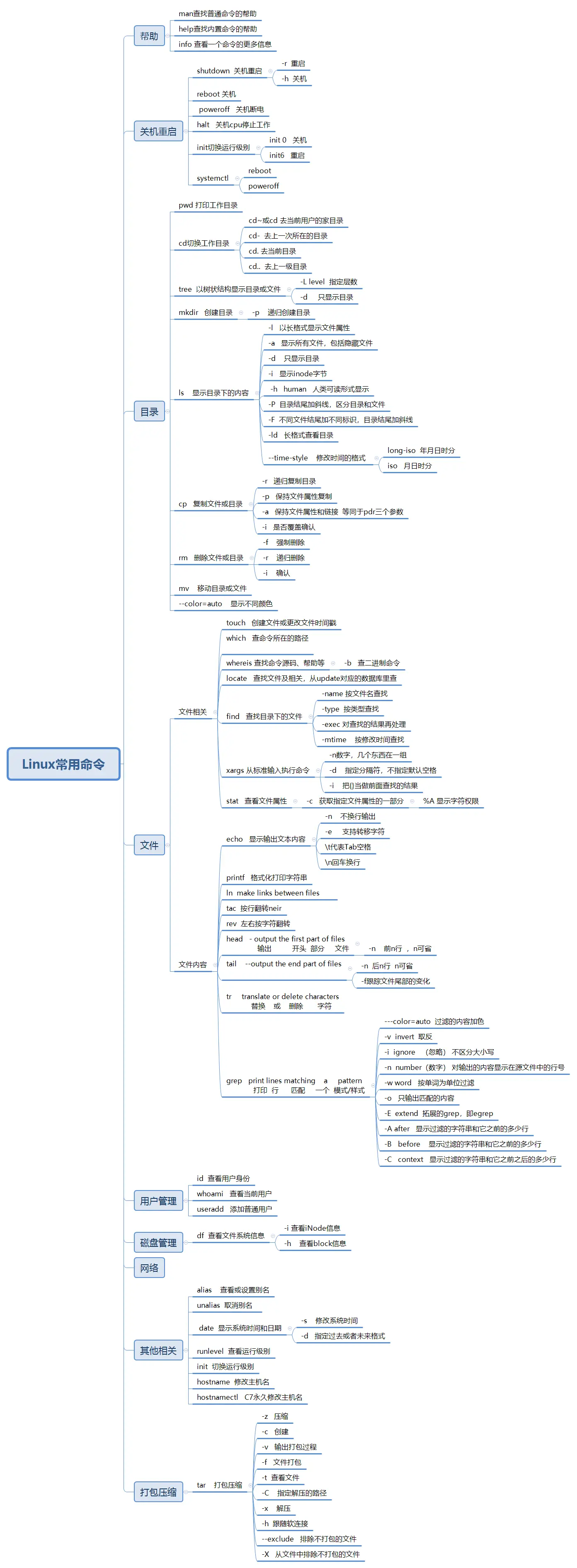
常用命令:
常用流程图
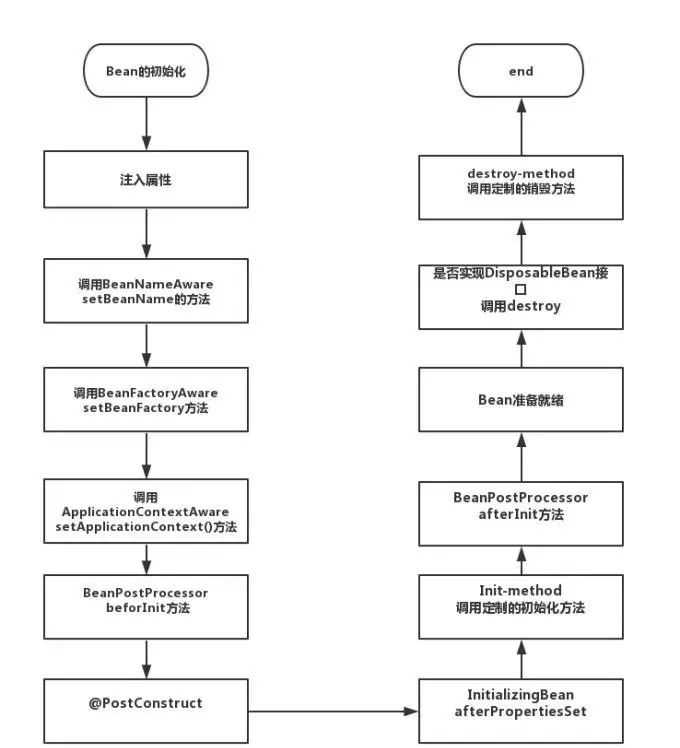
- spring生命周期
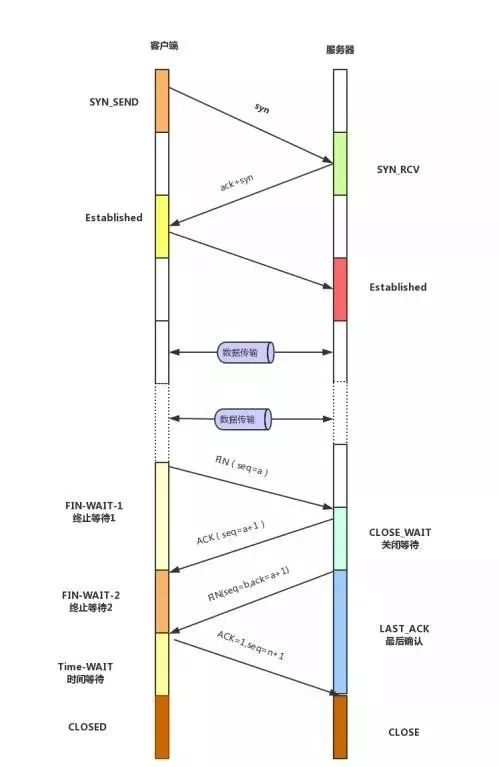
- tcp握手挥手
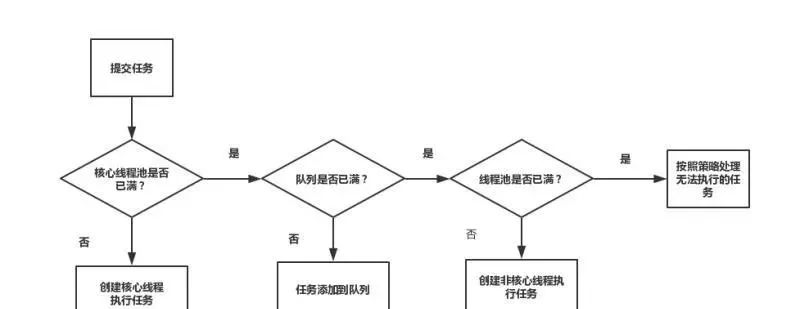
- 线程池执行
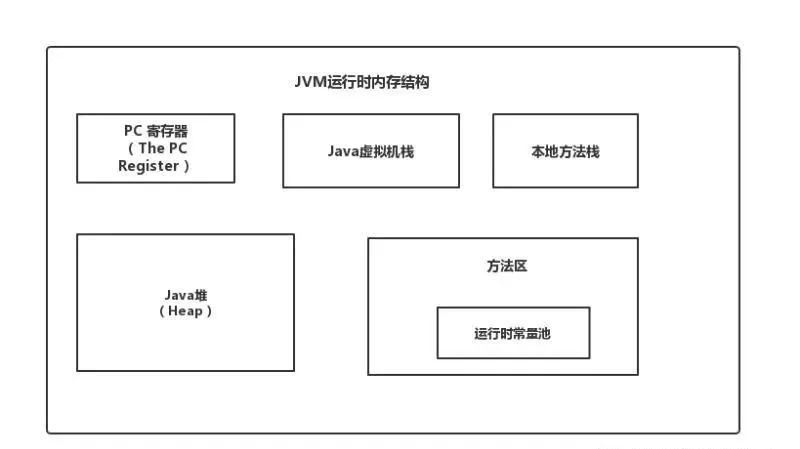
- JVM内存结构
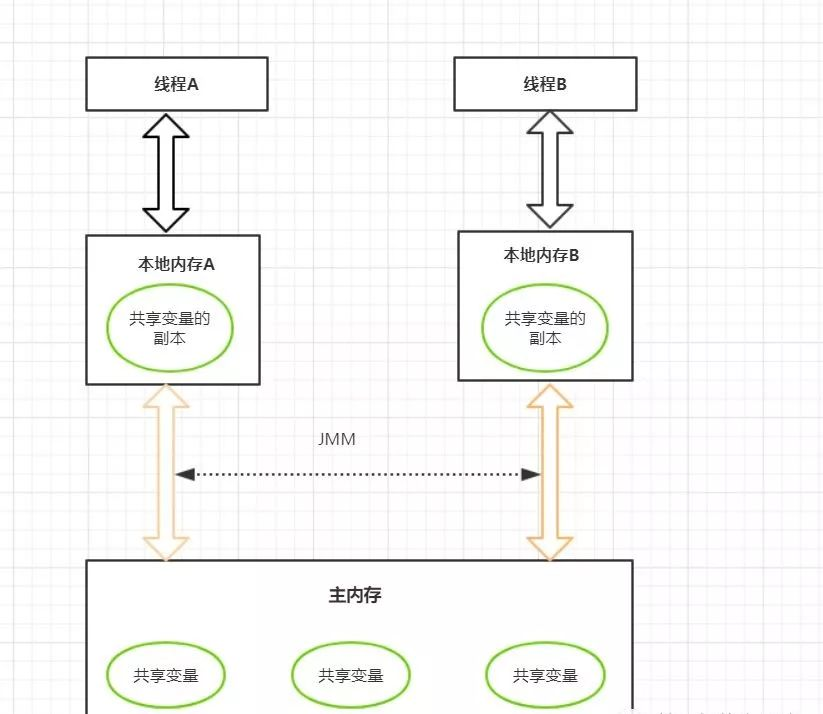
- Java内存模型
- springMVC执行流程

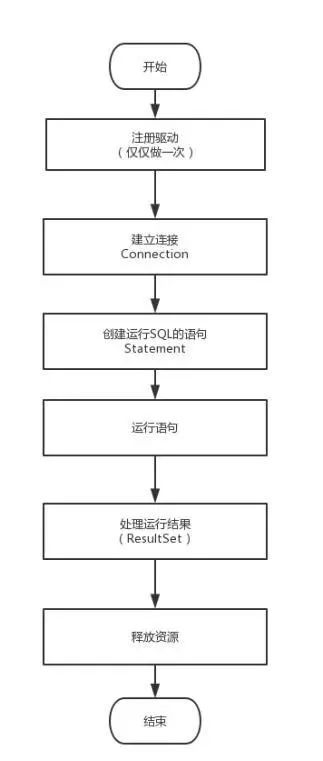
- JDBC执行流程
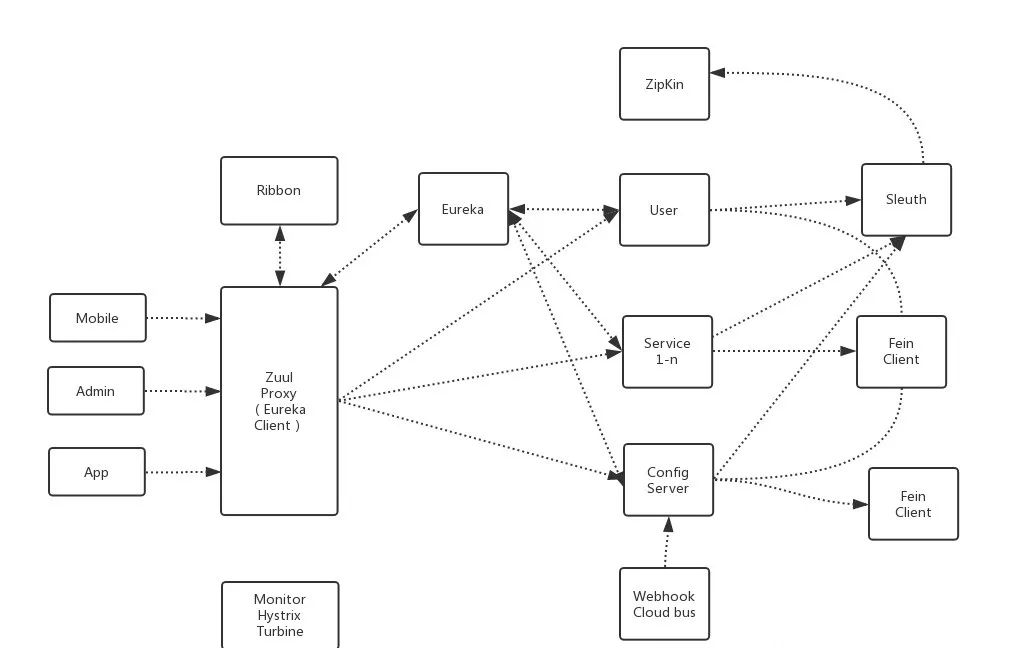
- spring cloud组件架构
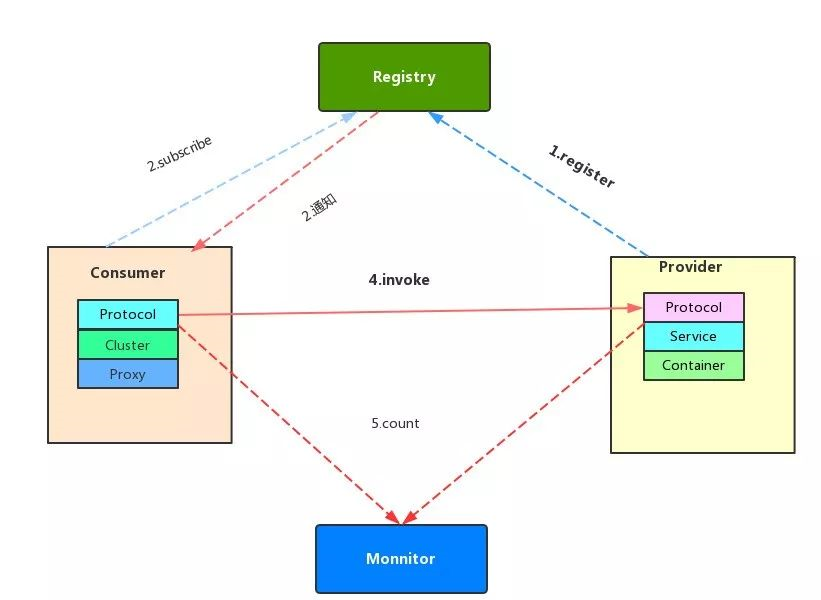
- dubbo调用
线程顺序执行的8种方法
- 使用线程的join方法
- 使用主线程的join方法
- 使用线程的wait方法
- 使用线程的线程池方法
- 使用线程的Condition(条件变量)方法
- 使用线程的CountDownLatch(倒计数)方法
- 使用线程的CyclicBarrier(回环栅栏)方法
- 使用线程的Semaphore(信号量)方法
分库分表思路
数据拆分主要分为垂直拆分和水平拆分。垂直拆分比较简单,也就是本来一个数据库,数据量大之后,从业务角度进行拆分多个库。水平拆分的概念,是同一个业务数据量大之后,进行水平拆分,一般是单表数据量过大拆分多表。
分库分表方案中有常用的方案,hash取模和range范围方案。分库分表方案最主要就是路由算法,把路由的key按照指定的算法进行路由存放。
-
hash取模方案——优点:分布均匀,不会有同一时间段记录访问的热点问题;缺点:不易扩容、迁移数据
-
range范围方案——range方案也就是以范围进行拆分数据。比如0-1000w存第一张表,1000w-2000w存第二张表,以此类推。优点:容易扩容,无需做数据迁移;缺点:容易产生热点问题。